Beau, J.: Inforespace n° 112, juin 2006, pp. 41-42.
| Home | English translation |
|---|
Depuis de nombreuses années, un grand nombre de bases de données ufologiques a été développé. Leurs incompatibilités mutuelles empêchant tout échange de données, leur prolifération a constitué un archipel où l’absence de voies navigables empêche toute communication nécessaire à la recherche et l’accès à la connaissance en général. Le remplacement de ces îlots de données par des îlots plus grands, issus de fusions, ne fait qu’accroître le problème, sans stopper la prolifération. Mais la question est là : faut-il la stopper ou en tirer parti ?
En ufologie comme ailleurs, le but d’une base de donnée est de structurer l’information pour lui appliquer des traitements automatisés. Retrouver un cas en un clin d’œil, les lieux d’observation pour une date donnée, dégager des tendances sur une période déterminée, ne sont que des exemples d’une multitude d’opérations proposées par les bases ufologiques d'aujourd’hui.
|
Un paradoxe les touche cependant : si chacune vise à étudier le même phénomène, aucune ne travaille sur les mêmes données. De sorte, chacun de ces îlots de données est un monde en soi, en autarcie, que ses oeillères amènent à développer une cohérence propre : sélection de données, traitements adaptés et bien évidemment résultats deviennent rapidement spécifiques au monde auquel ils appartiennent, et sont toujours différents de ceux des mondes voisins. Il n’en faut pas plus pour cristalliser l’ufologie en autant de chapelles.
Le problème est donc moins de travailler sur ses données que de ne pas avoir pas accès à celles des autres. Un peu comme s'il vous fallait une paire de lunettes différente pour lire chaque livre. De plus, les données des bases ufologiques, bien que parlant toutes de la même chose, ne racontent pas la même histoire : leurs cas plus ou moins nombreux, leurs détails, leurs sources, leurs évaluations subjectives même, sont autant de caractéristiques qui devraient offrir une nouvelle perspective au sujet d'étude des ufologues. Il faut lire tous ces livres, ceux existants et ceux à venir, afin de compléter, comparer, et enrichir les points de vue.
Une idée pour résoudre ce problème a été de fusionner les bases. Constituer un grand livre qui regroupe les données des plus petits. Tout laisse cependant penser qu’il s’agit d’un remède pire que le mal. Non seulement ce grand livre reste un livre, un livre de plus, avec la même vision autarcique et pleine d’inertie du sujet, mais il ajoute des défauts supplémentaires : une réalisation à la difficulté exponentielle – construire la somme de livres, puis la sommes des sommes, etc. pendant que d’autres bases naissent – mais aussi un compromis de dilution des données : là où il n’y a la place que pour une information fusionnée, il n’y a plus de place pour les différences qui constituent, elles aussi, une information en soi.
Même en considérant que le but d’une telle base soit de ne stocker qu’une seule vérité (idéalement objective, dénuées d’erreurs), il ne restera qu’à espérer de choisir la bonne. De fait, la fusion est partisane. Par essence, elle ne peut que mécontenter une partie des utilisateurs. Parce qu’elle ne contiendra pas les données auxquelles ils accordent crédit, parce qu’elle n’adoptera pas la structure qui leur convient, parce que les traitements qu’ils attendent feront défaut, parce que si elle n’était pas illusoire, elle ne serait au mieux que le réceptacle d’une pensée unique, et le frein à toute innovation. Les outils n'ont pas à trier les données, c'est le travail des ufologues.
Si on ne peut aller contre la nature d’archipel de la base des connaissances, il faut l’exploiter. Au lieu d’imposer un grand livre fusionné, laissons les données là où elles sont, au format qui leur convient, et regardons-les avec de grandes, grandes meta-lunettes.
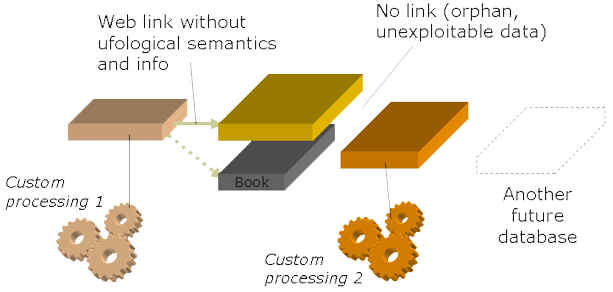
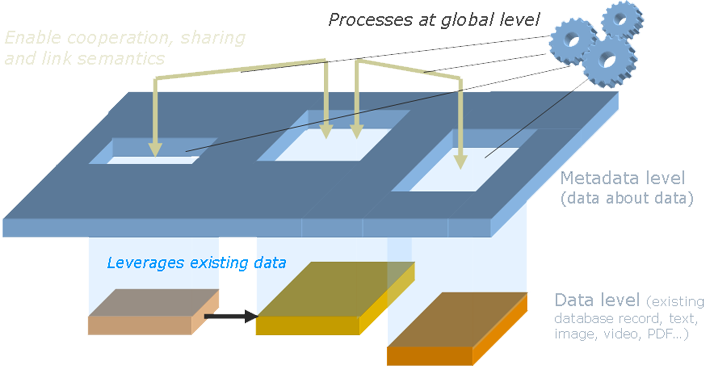
Une meta-base ne contient pas de données. Ou plutôt, des données bien particulières, des données qui décrivent les données : Où se trouvent les bases qui décrivent tel cas ? Quel type de données stocke telle base? Que signifie son champ X ? A-t-il la même signification que le champ Y de telle autre base ? C’est là le type d’informations stockées dans une meta-base. Chaque fois qu’une nouvelle base apparaît, sa description y est enregistrée.
 |
Grâce à ces informations, une meta-base, si elle ne contient pas les données effectives, devient capable d’aller les chercher : se connecter via Internet à une 1ère base en ligne, invoquer le formulaire de recherche d’une 2ème, aspirer les pages d’une 3ème. Les données ne sont en effet pas limitées aux bases proprement dites : il s’agit de toute information accessible, et dont la structure est descriptible.
Mais au fait, quel intérêt pour une telle source de données d’être reliées à une meta-base ? Avant de parler même d’intérêt, il s’agit d’une conviction : les données sont là pour être partagées par tous, pour le bien même de la recherche. Ensuite, relier sa base à une meta-base, c’est se brancher sur un réseau où l’information circule, et où l’on peut donner comme recevoir. L’information n’est virtuellement plus ici ou là, susceptible d’être perdue, mais capable de voyager, vers des collaborateurs, vers d’autres lieux de sauvegarde, où vers d’autres structures techniques constituant la prochaine génération de votre propre base. Combien de données se trouvent-elles aujourd’hui coincées, au risque de disparaître, dans leur logiciel qu’il serait trop coûteux et compliqué de faire évoluer ?
Mais une meta-base resterait d’un intérêt limité si elle n’était guère plus qu’un index ou un réseau de bases. Que diriez-vous de voir toutes les bases à la fois ? Cela semble a priori impossible, ou du moins peu exploitable. Comment un utilisateur pourrait-il tirer parti de toutes ces données et structures différentes à la fois ?
Effectivement, une telle vision "totale", même si elle devient possible, n’est pas exploitable telle quelle. De fait, appliquer des traitements implique un modèle de données commun. Or ce modèle, nous le savons, n’existe pas. Il est propre aux bases qui stockent les données, et nous savons qu’on ne peut imposer un modèle universel, tant chacun en a sa propre vue.
Mais, une vue, n’est-ce pas après tout que ce que nous cherchons à fournir ? Comme un calque appliqué sur les données totales, où se dessineraient les liens qui relient des concepts communs ? Ce modèle de données virtuel est concevable. Potentiellement différent pour chacun, n’existant qu’au niveau meta, c’est un meta-modèle.
Un tel meta-modèle est indépendant des modèles des bases. En conséquence, tous les traitements qui s’y appliquent, s’ils exploitent diverses données hétérogènes au travers du méta-modèle, en restent eux aussi indépendants. C’est là une séparation cruciale : le modèle de travail et ses traitements ne sont plus condamnés à mourir avec la base à laquelle ils s’appliquaient. On peut commencer à capitaliser dessus.
On l’aura compris, l’introduction d’un niveau meta au-dessus des bases n’est pas une fusion. En fait, c’est là même la philosophie même de la démarche : permettre une exploitation commune des données, sans gommer les différences. Il ne fait pas de doute que nombre meta-modèles différents cœxisteront, et seront incompatibles entre eux (quoique rien ne les empêche d’être réunis à un niveau méta supérieur encore, selon le même principe). Il ne fait pas de plus doute que nombre de bases choisiront de rester hermétique aux meta-bases. Mais plus que de rassembler l’ensemble des bases existantes et à venir, l’important est de rendre la chose possible. Demain, l’excuse technique au non partage des données, au cloisonnement de l’information, ne sera plus valable, et il faudra en assumer le choix.
___
Jérôme Beau, 32 ans, est ingénieur en informatique responsable d’une équipe de Recherche et Développement chez un éditeur de logiciels français spécialisé dans l’accès aux données. Il actif en ufologie depuis 1998, où il a commencé à créer le site RR0. Depuis 2003 il s’est investi dans la conception et le développement d’outils ufologiques, tels que les projets UFO@home et Archipelago.
| Home | English translation |
|---|