Beau, J.: Inforespace n° 112, june 2006, pp. 41-42. Translated by Terry Groff, DFW MUFON.
| Home > Archipelago | Traduction française |
|---|
Over the past several years there have been many ufological databases developed. Since their mutual incompatibilities has prevented data exchange, their proliferation has created a kind of archipelago where the lack of naviguable paths has prevented the communication required for the research and knowledge access in general. The unification of data islands into larger ones seems to only increase the problem, while having no effect on proliferation. The question is: should proliferation be stopped or leveraged?
In ufology, as in any other area, the goal of a database is to structure information for the application of automated processes. Finding a case in an instant or sighting location for a given date or determining trends on any given date range are only a few examples of a operations that are offered by ufological databases today.
However they are all affected by the same paradox: while each of them aims to study the same phenomenon, none work on the same data. As a result, each of those data islands is a world as itself, in autarky, with its own consistency auto-developed: its own data selection, its own processes, and its own results, that always don’t fit those of its neighbors. You don’t need more to crystallize ufology as many doctrines.
However the problem is less about working on your data than not having access to other’s. Just like if you had different glasses for each book you may want to read. Databases are our glasses, but are quite useless if they only allow us to read a single book. Even if data from databases are talking about the same thing, they don’t tell the same story. Their cases, more or less numerous, their details, their sources, even their subjective evaluations are as much features that add a new perspective to the topic we study. We have to read all those books, the existing ones as much as the ones to come, to complete, compare, and enrich our viewpoints.
|
One idea to solve this problem has been to unify existing databases. To build a big book that would gather data from the smaller ones. However, it seems that such a cure may be worse than the disease. Not only that the big book remains as a book, again with single glasses, and with the same autarkical and full-with-inertia vision of its topic, but also that it adds new weaknesses as well.
It becomes exponentially difficulty to implement – build the sum of existing books and then the sum of the sums and so on – while new databases are still emerging, but also having to compromise over the dilution of data.
When you put unified data in a single location only, you can’t leverage the differences from original data which constitute, in themselves, valuable information. Even if you consider that a database contains valuable information (ideally objective, fixed and without error), you still have to pray that the good data is selected. Unification of data requires selecting good data. That process ignores data that has not been selected. As it is, it may be disagreeable with some of the potential users, because:
If we can’t go against the very archipelago nature of the knowledge base, we have to leverage it. Instead of building a big unified book, let’s the keep the data where it lies, using the structure it requires, and let’s look at it using big, big meta-glasses.
A meta-base doesn’t contain data. More precisely, it contains very special data, that is, data that describes data: Where are the databases that contain data about a given case? What type of data this database stores? What is the meaning of the X field? Has it the same meaning as the Y field from another database? This is the type of information that is stored in a meta-base. Each time a new database appears, its description is recorded therein.
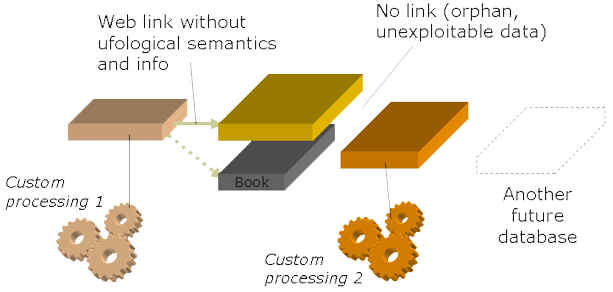
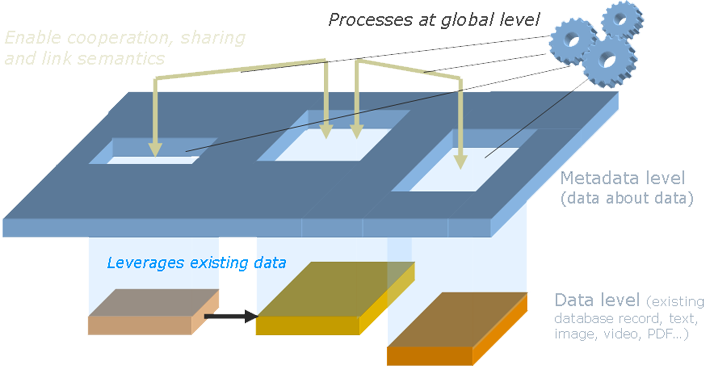 |
Thanks to such information, a meta-base, even if it does not contain the actual data, becomes able to retrieve it; to connect through the Internet to a primary online database, invoke the search from a secondary one, aspire the pages of a third one. Indeed, data is not limited to databases in the strict sense: it is any accessible information, whose structure can be described (a database record, a Web page, a XML file, etc.).
What could be the benefit for such a data source being linked to a meta-base? Before talking about benefit, there is a matter of conviction. First, data must be shared with everyone, for the sake of efficient research. Furthermore, linking your database to a meta-base is plugging into a network where information flows, and thus where you can provide as much as you are able to receive. Information is virtually no longer here or there, likely to be lost, but now able to migrate, toward fellows, other users, towards other backup locations, or toward other technical structures that may constitute the next generation of your own database. How much data is today stuck into an existing database, likely to disappear along with a software that would be too costly and complicated to evolve?
But a meta-base would remain quite limited if it wouldn’t be more than a database index or network. What about seeing all databases at the same time? This seems impossible, or at least not very practicable. How could a user benefit from all of this different data and structure at the same time?
Indeed, such a « global » vision, even if possible, is not practicable as is. Applying processes implies a common data model which, we know, doesn’t exist. It is specific to the databases that store data, and we know that we cannot enforce a universal model, as everyone has their own view.
But isn’t such a view what we are willing to provide? Just like a pattern applied to the global data on which would be drawn links between common concepts? Such a virtual data model is conceivable. Being potentially different for each of us, existing at the meta level only, it is a meta-model.
Such a meta-model is independent from the databases. As a result, each of the processes applied to it, while leveraging heterogeneous data through the meta-model, are also kept independent from them. Here is a fundamental separation. The working model and its associated processes are no longer condemned to die with the database to which they are applied. We can then start capitalizing on them.
As we have shown, introduction of a meta level above databases is not unification. One size doesn't fit all. Actually, this is indeed the very philosophy of the idea: to allow a shared leveraging of data, without erasing differences. There is no doubt that a number of different meta-models will coexist, and be incompatible with one another, but nothing would prevent them from being accessible at the meta level, according to the same principle. There is no doubt also that a number of databases will choose to stay away from meta-bases. But, more important than effectively gathering all existing and future databases, the crucial point is to make it possible. Tomorrow, data and results will be accessible and comparable through compatible meta-levels and data networks. Then, the technical excuse for not sharing data and information compartmentalization will no longer be valid, and one will have to assume such a choice.
___
Jérôme Beau, 33, is a sofware engineer who is responsible of a Research & Development Team of a french software editor which is specialized in data acces. He is active in ufology since 1998, when il started building the RR0 website. Since 2003, he is involved in designing and developing sofware tools for ufology, among which are the UFO@home and Archipelago projects.
| Home > Archipelago | Traduction française |
|---|