Architecture
Architecture d'un serveur Archipelago
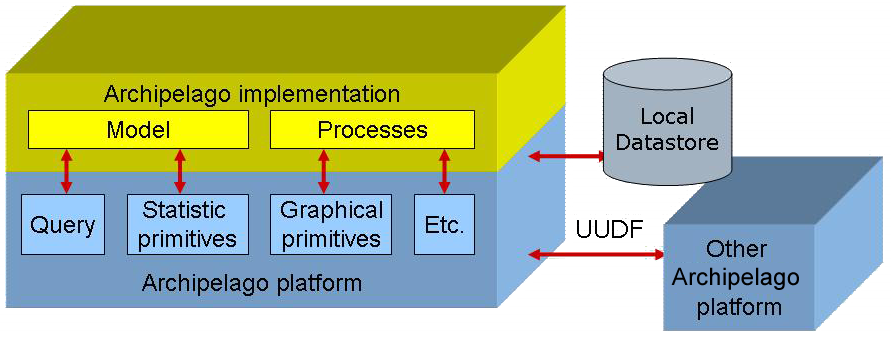 |
Tout comme les bases de données classiques, Archipelago est un serveur. Comme les meilleures d'entre elles, il est plus que cela, permettant d'appliquer des traitements sur les données qu'il fournit. Comme peu d'entre elles, il propose une vision de données sous forme d'objets représentant les concepts ufologiques de l'utilisateur indépendamment des contraintes techniques. Comme aucune d'entre elles, il ne stocke pas véritablement mais virtuellement les données, se bornant à permettre d'y accéder.
Dans tout serveur Archipelago se trouve donc 2 grands blocs principaux :
- la plate-forme, identique à tous les serveurs, qui fournit les services techniques (manipulation des données, interface graphique) et de base (gestion des utilisateurs)
- le modèle de données et traitements mis en place par l'utilisateur. En fait, un serveur peut héberger plusieurs modèles qui peuvent être utilisés, voire même partagés par les utilisateurs.
Intégration
Architecture d'integration
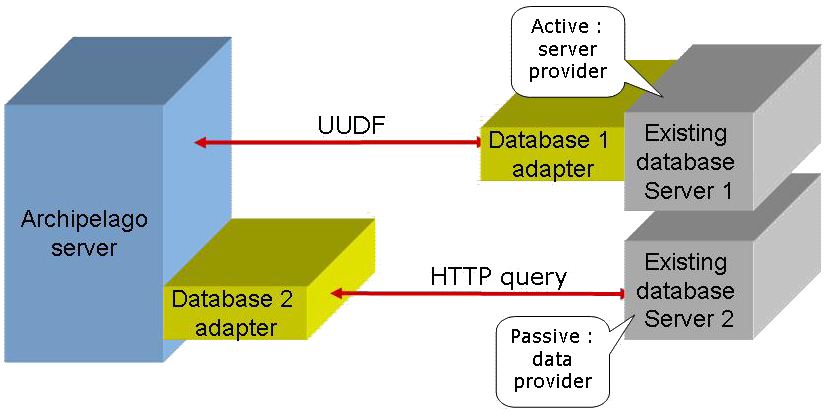 |
Une base de données existante peut s'intégrer avec un serveur Archipelago de 2 manières :
- passive : c'est le serveur Archipelago qui va chercher les données (pull). Cette stratégie peut être motivée par diverses raisons :
- pas de logique du côté base de données (juste un fichier ou une page web, typiquement)
- pas de temps, ressources ou de volonté de développer un adaptateur Archipelago.
- active : c'est la base qui envoie (push) ses données au serveur Archipelago. Cette stratégie peut également être motiviée par diverses raisons :
- volonté de promouvoir le partage des données
- volonté de collecter des données d'autres bases, à travers la couche meta de Archipelago
- volonté de migrer ou sauvegarder les données vers une autre base de données
- volonté d'utiliser les processus hébergés par le serveur Archipelago.