Architecture
Server architecture
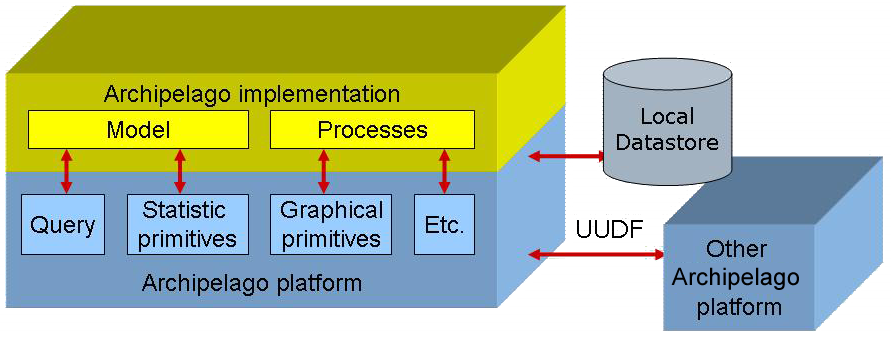 |
Like classical databases, Archipelago is a server. Like the better of them, it is more than that, allowing to apply processes on the data it provides. Like a few of them, it offers a vision of the data as objects, representing the user ufological concepts independently of technical constraints. Like none of them, it doesn't store data actually but rather virtually, and just focuses on allowing access to them.
As a result, each Archipelago server is composed of 2 main blocks :
- the plateform, the same in every server, which provides technical (data manipulation, graphical interface) et basic (user management) services
- the data and processing model set up by the user. Actually a server can host several models, which can be used and even shared by users.
Integration
Integration architecture
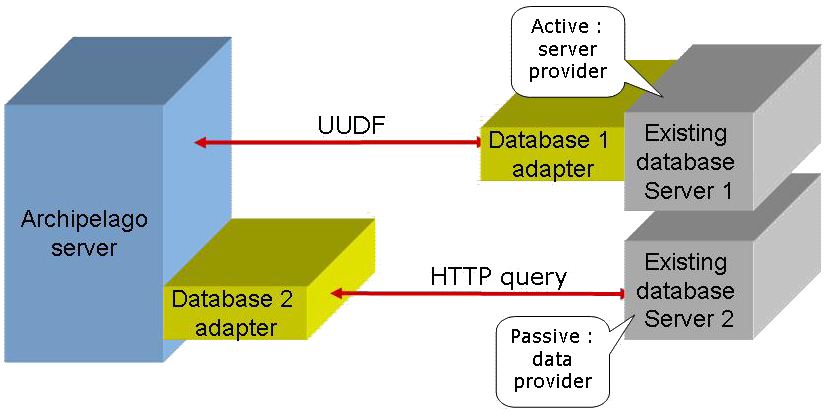 |
An existing database can integrate with an Archipelago server in 2 ways :
- passive : the Archipelago server retrieves (pull) the data from the database. This strategy can be motivated by various reasons :
- no logic on the database side (just a file or a web page, typically)
- no time, resources or will to develop an Archipelago adapter
- active : the database sends (push) its data to the Archipelago server. This strategy can also be motivated by various reasons :
- will to promote data sharing
- will to gather data from other databases though the Archipelago meta layer
- will to migrate or backup data to another database
- will to use processes hosted by the Archipelago server